

Have you noticed that lately a lot of posts or episodes in the IT Division Blog have audio entries associated with them? The voices in the narration sound quite natural. But more importantly, the sound is clean and without the sounds of dogs barking, leaf blowers, or children in the background. Where are the recordings taking place and how can you get in on this?
Listen to a recording of this post:
A while back I started to think about audio production for things like blogs and podcasts. I approached it from the perspective that not everyone will have everything needed to create podcasts, let alone the time, especially when resources are scarce. I figured we could repurpose content we already have or are currently producing. The content could be repurposed to create media without investing in additional equipment and adding additional work to people already busy with a ton of other things on their plates.
Enter artificial intelligence services. More specifically, text-to-speech services. Microsoft, as part of its Azure services, offers a what-you-see-is-what-you-get (WYSIWG) service that requires very, very little coding to turn existing text into recorded speech. I started copying and pasting my blog entries into Speech Studio, and after some poking around settled on two types of voices called “neural voices.” In my case, I chose the voice of a British man, and the voice of an American woman, that would read different sections of the entry to make it sound more like a broadcast.
Neural text-to-speech is a new type of speech synthesis powered by deep neural networks. When using a neural voice, synthesized speech is nearly indistinguishable from the human recordings. Neural voices can be used to make interactions with chatbots and voice assistants more natural and engaging, convert digital texts such as e-books into audiobooks, and enhance in-car navigation systems. With the human-like natural prosody and clear articulation of words, neural voices significantly reduce listening fatigue when users interact with AI systems.
After pasting the text into Speech Studio, I do a bit of tweaking to the “script,” just enough to make it more engaging.
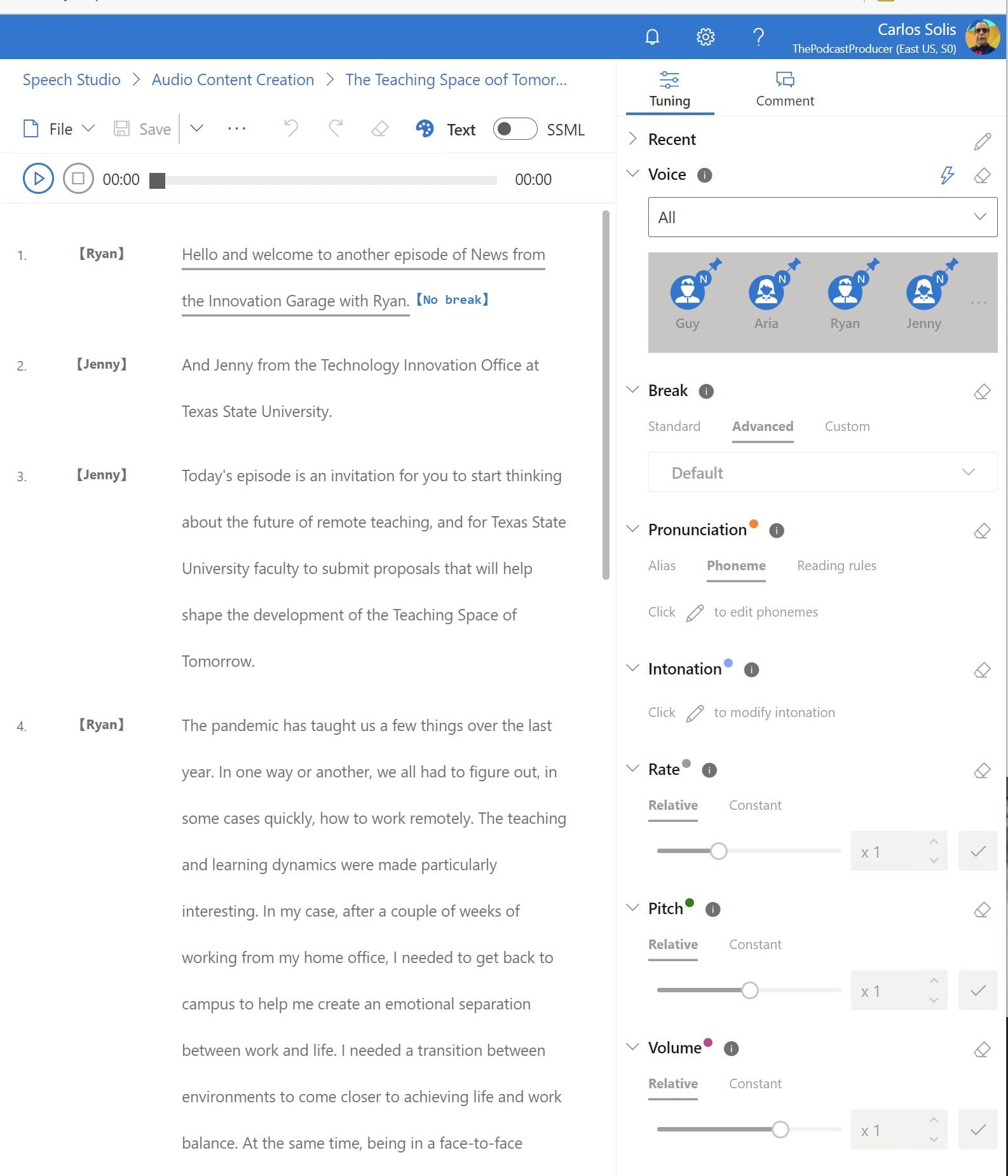
One of the advantages to using Speech Studio is that errors in the recording can easily be corrected by editing the text. In comparison, when I make an error in a traditional audio recording, I would need to either re-record the whole thing or find audio-editing tools to cut out errors. In Speech Studio, it’s as easy as cut and paste to replace. Re-rendering an audio file is fast and easy and is a lot less time consuming.
From there, Speech Studio produces a downloadable .wav sound file that can be loaded onto a podcasting platform. As a result, we can embed that episode into an IT Division blog entry. Additionally, one can also find the recordings on the podcast platform, which means you could listen to the posts on the go. As we move forward, we can conceive further refinements and future applications.
With this approach we have made our publications more professional and have brought them up to other industry practices. Users can engage with content in multiple ways and in multiple platforms with a single workflow.
Bottom line? Innovation comes from looking at a problem that needs a solution and thinking outside the current norm to envision a new process and product. Here, we are leveraging cloud services and artificial intelligence to free ourselves from recording studios and equipment. We are no longer constrained by having to identify voice talent, editing text to produce and correct audio, and feeding multiple media platforms from a single asset.
Dr. Carlos Solís is Associate Vice President of the Technology Innovation Office.
